Introduction
The aim of this article is to take your from having nothing installed on your local Windows machine to being able to spin up an an AWS Windows instance which has Sql server CE installed using Vagrant, Packer and Chef. This tutorial makes the assumption you are using a Windows machine to install the software below.
The tutorial is split into two parts. Part one focuses on creating a customized Windows image which allows us to install software to the machine using Chef. This is referred to as an AMI (Amazon Machine Image). Part two focuses on spinning up an AWS instance using that AMI and installing Microsoft Sql Server using the Chef component which we baked into the AMI.
Before I start I would like to thank the author of the base document of which I built my knowledge on:
http://engineering.daptiv.com/provisioning-windows-instances-with-packer-vagrant-and-chef-in-aws/
Whilst this gave me the basics, there were a few key modifications and additional steps required to actually get the instance up and running which I have documented here.
Disclaimer
The instance created only has very basic security policies in place and would require changes in order to make this production secure. The purpose of this tutorial is to focus on the getting the instance up and running as opposed to making it production ready
Prerequisites
You will need to install the following:
- An AWS account
- A Windows machine
- Vagrant software downloaded (https://www.vagrantup.com/downloads.html)
- Packer software downloaded (https://www.packer.io/downloads.html)
- Sublime or equivalent text editor (https://www.sublimetext.com/download)
Explanation of software installed
AWS : Amazon web services: used to host to windows instance you have created
Vagrant software: used to specify the configuration of the machine to create in AWS
Packer: additional software required to create a using AMI (Amazon Machine Image) in AWS
Sublime: text editor to make changes to Vagrant files, Packer files and configuration settings
Customizing the PATH variable
We need to be able to use the software we have installed at the command prompt. In order to do this we must ensure the application directories have been added to the PATH variable. If you’re unfamiliar with editing your windows PATH variable you can find a tutorial here:
http://www.computerhope.com/issues/ch000549.htm
Once you have made the changes your PATH variable should look something similar to this (Windows 10):
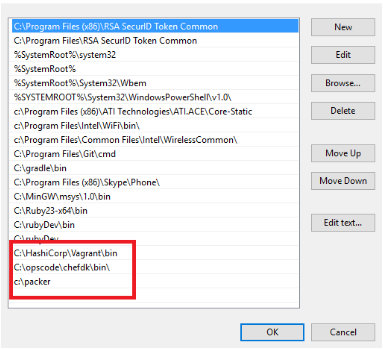
Customizing the software:
Vagrant by default is not set up to spin up instances in AWS. We need to install a number of plugins before it is ready to use. Open a command prompt and type the following command:
Vagrant plugin list
This will show the following plugins installed by default. We need to install the following plugins and remove some existing plugins in order for this process to work
Plugins to install:
Nokogiri (1.6.7.1) See notes below before installing
Vagrant-aws See notes before to install
vagrant-share
vagrant-winrm-syncedfolders
Plugins to remove:
Any references to berkshelf
To install a plugin type the following command:
Vagrant plugin install [name of plugin with no brackets]
E.g. vagrant plugin install vagrant-share
Notes on installing vagrant-aws plugin:
At the time of writing Vagrant was not working through the plugin install method so you will have to download and install it manually. This can be done by:
- Navigating to rubygems.org (https://rubygems.org/gems/vagrant-aws)
- Click the download link
- Open a command prompt and type vagrant plugin install /path/to/my-plugin.gem (e.g. c:\awsTest\awsPlugin.gem)
If your windows user home directory name contains spaces then you will receive an error asking you to move your Vagrant Home folder to a location without spaces. This can be done following these instructions (https://issues.jboss.org/browse/JBDS-3653)
To remove a plugin type the following command:
Vagrant plugin uninstall [name of plugin with no brackets]
A Note on Nokogiri:
In order to install this plugin successfully you will need to make some changes to the Vagrant configuration itself. You will need to edit the following Vagrant configuration files:
vagrant.gemspec and vagrant-1.8.1.gemspec
These can be located in the following location (if you installed Vagrant in the default location):
C:\HashiCorp\Vagrant\embedded\gems\specifications
In the files locate any reference to nokogiri and change to reference to:
s.add_runtime_dependency(%q<nokogiri>, [“>= 1.6.3.1”])
Once you have saved your changes you can then install the plugin as standard:
Vagrant plugin install nokogiri
By the end of adding and removing plugins you should have the following plugins installed:
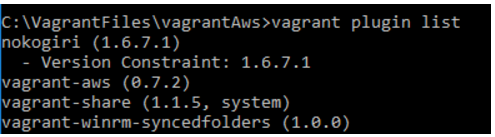
If you have the following error on installing any of the plugins:
[ error to resolve with aws plugin: Could not find gem ‘vargrant-aws x86-mingw32’ in any of the gem sources listed in your Gemfile or available on this machine.]
Make sure you check your spelling of the plugin as this can cause issues
Setting Up AWS
A security group defines what and who can and cannot access your Amazon instance. We need to ensure this group allows WinRM access. This is the protocol required for your local machine to talk to the AWS instance in order to issue commands. Non Windows AWS commands use SSH to communicate. Windows AWS instances use WinRM
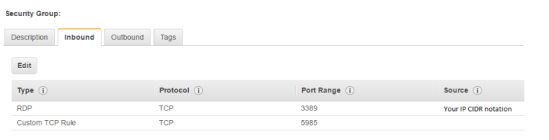
You need to create a new inbound rule with the following details:
Type: Custom TCP rule
Protocol: TCP
Port Range: 5985
Source: select myIP – This is your publicly available IP address
Type: RDP
Protocol: TCP
Port Range: 3389
Source ip: your publicly available ip address in the same format as above
You should also select the VPC as default for ease of use for this tutorial.
Your security rule should look something like this:
Creating the Packer file
Packer is responsible creating an AMI which we can then use Vagrant to spin up an instance from. We cannot by default spin up the Amazon Windows instances that are already available as they lack certain configuration settings for WinRM and do not have Chef installed (to allow us to install more software onto the box)
First we need to create a packer file. Create the following file: aws.json in the folder where you have installed Packer and open it with your text editor. Next paste the following information into the file
{
"builders": [{
"type": "amazon-ebs",
"region": "ENTER_REGION_HERE",
"instance_type": "t2.micro",
"source_ami": "ENTER_SOURCE_AMI_HERE",
"ami_name": "windows-ami-01",
"user_data_file": "bootstrap-aws.txt",
"communicator": "winrm",
"winrm_username": "Administrator",
"winrm_password": "ENTER_AT_LEAST_18_DIGITS_NUMBERS_LETTERS_SYMBOLS",
"winrm_timeout": "4h",
"subnet_id": "ENTER_SUBNET_ID_HERE",
"security_group_id": "ENTER_SECURITY_GROUP_HERE",
"access_key": "ENTER_ACCESS_KEY_HERE",
"secret_key": "ENTER_SECRET_KEY_HERE"
}],
"provisioners": [{
"type": "powershell",
"scripts": [
"install-chef.ps1"
]
}]
}
Let’s talk through the fields you will need to populate with your own data.
ENTER_REGION_HERE: This is where you specify the Amazon region of where to spin up the AWS instance. It’s recommended you spin up an instance closest to you for geographical latency. At the time of writing the regions you can enter are: (enter only one)
US East (N. Virginia) us-east-1
US West (N. California) us-west-1
US West (Oregon) us-west-2
Asia Pacific (Mumbai) ap-south-1
Asia Pacific (Seoul) ap-northeast-2
Asia Pacific (Singapore) ap-southeast-1
Asia Pacific (Sydney) ap-southeast-2
Asia Pacific (Tokyo) ap-northeast-1
EU (Frankfurt) eu-central-1
EU (Ireland) eu-west-1
South America (São Paulo) sa-east-1
For example to select EU (Frankfurt) you should enter the following in the region field: eu-central-1
ENTER_SOURCE_AMI_HERE: This is where you enter the source base Amazon image you wish to customize. Here you need to enter the the current id of the Windows Server 2012 R2 Base image. This can be found by logging into AWS -> Selecting EC2 Under the compute section -> Selecting launch instance. This will provide you a list of AMI’s. In the packer file enter the id on the Windows server image:
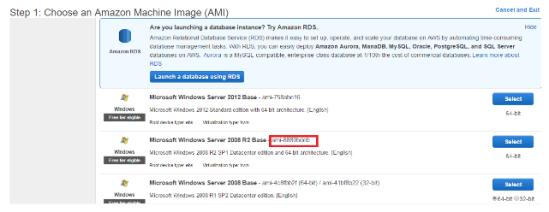
E.g ami-XXXXXX
User data file explained:
This allows us to execute commands the first time the AWS instance spins up. Create a file called bootstrap-aws.txt in the same folder as the Packer folder. Paste the following text into the file:
<powershell>
# set administrator password
net user Administrator Kopfwokfewpokfweksalkdsokdsokkokpfs111#
wmic useraccount where "name='Administrator'" set PasswordExpires=FALSE
# configure WinRM
winrm quickconfig -q
winrm set winrm/config/winrs '@{MaxMemoryPerShellMB="0"}'
winrm set winrm/config '@{MaxTimeoutms="7200000"}'
winrm set winrm/config/service '@{AllowUnencrypted="true"}'
winrm set winrm/config/service/auth '@{Basic="true"}'
netsh advfirewall firewall add rule name="WinRM 5985" protocol=TCP dir=in localport=5985 action=allow
net stop winrm
sc config winrm start=auto
net start winrm
# turn off PowerShell execution policy restrictions
Set-ExecutionPolicy -ExecutionPolicy Bypass -Scope LocalMachine
</powershell>
This file is overriding some of the default behavior which is associated with AWS and the base AMI we have selected. Firstly it is overriding the Administrator password of the image allowing us to login if to diagnose any issues. Next it is overriding some of the default settings of WinRM and then restarting the service. Finally it is disabling some of the Powershell restrictions that would normally be associated with this base image.
WinRM Password: This must be the same password you have just put in the user data file. Otherwise WinRM will not be able to connect to the instance.
ENTER_SUBNET_ID_HERE: Your default VPC will have set up a number of subnets to connect to different availability zones. You will need to select one only.
First go to to the AWS dashboard and select VPC:
Next Select Subnets:
From here you can use the id of the subnets created:
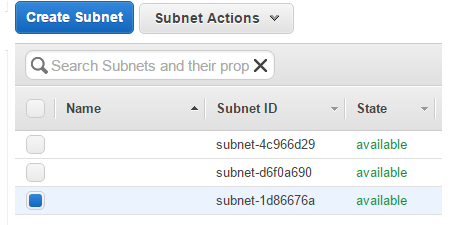
I would recommend entering the first Subnet ID into your packer file providing that when it’s selected the details below show the VPC ID which is tied to the security group ID you’re about to enter into the packer file.
ENTER_SECURITY_GROUP_HERE: Enter the security group id you created earlier in the tutorial. This can be found by going to the EC2 Dashboard -> Security Groups
The ID should start with sg-XXXXX
ENTER_ACCESS_KEY_HERE:
ENTER_SECRET_KEY_HERE:
The access key and the secret key provide a security layer to ensure an authorized machine is communicating with the AWS instance.
To create and Access key and Secret key you can use the AWS documentation here:
http://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSGettingStartedGuide/AWSCredentials.html
Once you have created a user with an access and secret key you will need to edit their permissions to enable them to create instances. Select the user and then select the permissions tab.Then click attach a policy:
For the sake of simplicity of the demo I would recommend the AdministratorAccess role.
The Provisioners section:
Let’s examine this section of the Packer script in more detail:
"provisioners": [{
"type": "powershell",
"scripts": [
"Install-chef.ps1"
Once the AWS instance is up and running it will execute a PowerShell script called install-chef.ps1. This is our script that we will now create to allow as to install Chef onto the AWS instance. Create a file in same folder as the Packer script you have just created and call it install-chef.ps1. Open the file and paste in the following contents:
$download_url = 'https://opscode-omnibus-packages.s3.amazonaws.com/windows/2008r2/i386/chef-client-12.4.2-1-x86.msi' (New-Object System.Net.WebClient).DownloadFile($download_url, 'C:\\Windows\\Temp\\chef.msi') Start-Process 'msiexec' -ArgumentList '/qb /i C:\\Windows\\Temp\\chef.msi' -NoNewWindow -Wait
Save and close the file.
The script explained:
The script creates a variable called download_url which informs the AWS instance of the download location of the Chef Client application. Next a new file is created on the AWS instance called chef.msi which the contents will be populated from the download_url variable. Finally msiexec is called to execute the newly download msi with the argument to bypass any user input whilst installing ( -NoNewWindow -Wait)
We’re now ready to execute the script! To do this open a command line prompt, navigate to to the Packer folder and type:
packer build aws.json
You should then see the following output:
C:\packer>packer build aws.json
amazon-ebs output will be in this color.
==> amazon-ebs: Prevalidating AMI Name...
==> amazon-ebs: Inspecting the source AMI...
==> amazon-ebs: Creating temporary keypair: packer 57e6ef5c-e5ce-aa68-d8bb-d
f8f9725
==> amazon-ebs: Launching a source AWS instance...
amazon-ebs: Instance ID: i-008fddf28eb2a36e5
==> amazon-ebs: Waiting for instance (i-008fddf28eb2a36e5) to become ready..
==> amazon-ebs: Skipping waiting for password since WinRM password set...
==> amazon-ebs: Waiting for WinRM to become available...
==> amazon-ebs: Connected to WinRM!
==> amazon-ebs: Provisioning with Powershell...
==> amazon-ebs: Provisioning with shell script: install-chef.ps1
==> amazon-ebs: Stopping the source instance...
==> amazon-ebs: Waiting for the instance to stop...
==> amazon-ebs: Creating the AMI: windows-ami-01
amazon-ebs: AMI: ami-cdb484ae
==> amazon-ebs: Waiting for AMI to become ready...
==> amazon-ebs: Terminating the source AWS instance...
==> amazon-ebs: Cleaning up any extra volumes...
==> amazon-ebs: No volumes to clean up, skipping
==> amazon-ebs: Deleting temporary keypair...
Build 'amazon-ebs' finished.
==> Builds finished. The artifacts of successful builds are:
--> amazon-ebs: AMIs were created:
ap-southeast-2: [AMI ID here]
Congratulations! You have successfully created an based AMI which we can now use create an instance from using Vagrant. If the output got stuck on “Waiting for WinRM” (more than a few minutes) then see the section below.
Debugging when something goes wrong
AWS has a number of useful tools to let you know what state the instance is in. When and AWS instance is running, navigate to the EC2 section of the AWS Dashboard:
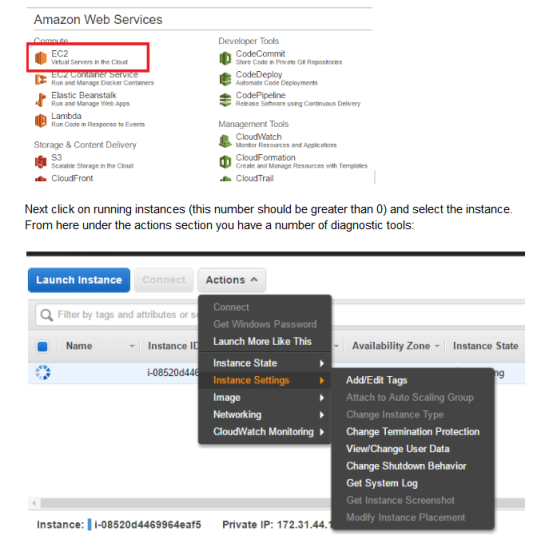
View/Change User Data: Allows you to edit what the instance will do once it has been launched. This is the same information contained in bootstrap-aws.txt file referenced in our Packer file. It can help to remove sections in here to see at what point there is a problem with the file.
Get System Log: Allows you to view data on the instance starting up to ensure there are no errors
Get Image Screenshot: This will grab a screenshot of your actual running instance. This can highlight of the instance is still starting up, is at the login screen or an error has occurred.
I Cannot log into the instance i have created using the Packer file
It is very likely that the password you created in the aws.json file and the bootstrap-aws.txt or either too simplistic or do not match. If this step fails then the rest of the bootstrap-aws.txt will not execute and you will be stuck on the waiting for WinRM process when “running packer build aws.json”
Stage 2: Using Vagrant to create an AWS instance from the AMI we created
What we have done so far is create an AMI (Amazon Machine Image) which we have customized so that:
- WinRM communication is possible
- We have installed a Chef client to enable us to install more software onto the instance.
The next part of the tutorial will spin up an AWS instance using our AMI and then install SQL server CE onto it using Chef
First create a folder called vagrantAWS and in this folder create a file called “Vagrantfile” (no extension)
Next in the Vagrantfile paste in the following text:
Vagrant.configure("2") do |config|
config.vm.box = "dummy"
config.vm.box_url = "https://github.com/mitchellh/vagrant-aws/blob/master/dummy.box?raw=true"
config.vm.provider :aws do |aws, override|
aws.access_key_id = "[AWS ACCESS KEY YOU CREATED IN FIRST PART OF THE TUTORIAL]"
aws.secret_access_key = "[AWS SECRET KEY YOU CREATED IN FIRST PART OF THE TUTORIAL]"
aws.ami = '[ID OF AMI YOU CREATED]'
aws.instance_type = 't2.micro'
aws.region = '[SAME AS IN PACKER FILE]'
aws.subnet_id = '[SAME AS IN PACKER FILE]'
aws.security_groups = ['[SAME AS IN PACKER FILE]']
# https://github.com/mitchellh/vagrant-aws/issues/340
override.nfs.functional = false # workaround for issue 340
override.winrm.username = "Administrator"
override.winrm.password = "[SAME AS IN PACKER FILE]"
override.vm.communicator = :winrm
end
config.vm.provision :chef_solo do |chef|
chef.add_recipe "windows"
chef.add_recipe "sqlce"
chef.file_cache_path = 'c:/var/chef/cache'
end
end
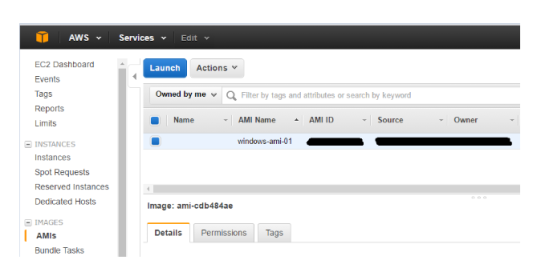
ID OF AMI YOU CREATED: At the end of the the successful run of ‘packer build aws.json’ you would have seen the following line:
–> amazon-ebs: AMIs were created:
ap-southeast-2: [ID OF AMI]
You can also find the ID of the AMI you created here in the EC2 dashboard:
What the Vagrantfile is doing
Firstly is it solving a number of known issues with Vagrant and AWS by creating a dummy image and also overriding the WinRm settings. The it is using the Chef recipe sqlce to install SQLCE onto the AWS instance.
Some Chef preparation:
In order to provision the AWS instance with SQLCE you will need to download the cookBook. First we need to create a cookbooks folder in the VagrantAws folder on your local machine.
Next download the SQLCE chef cookBook from here (and extract them to the cookbooks folder):
https://supermarket.chef.io/cookbooks/sqlce
You will also require the Windows cookbook which can be downloaded from here:
https://supermarket.chef.io/cookbooks/windows
You will also need Chef_handler:
https://supermarket.chef.io/cookbooks/chef_handler
You need to make sure you select the compatible versions in order for the tutorial to work. This can be done using the dropdown:
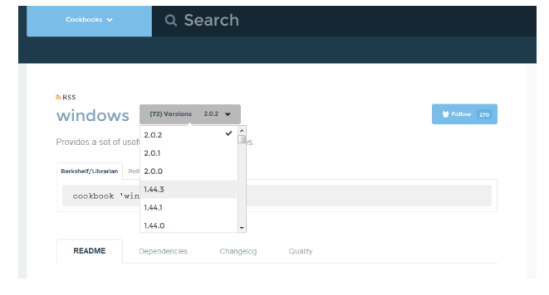
The versions you will need are
Windows – 1.36.1
SQL CE – 1.0.0
Chef_handler – 2.0.0
You will need a tar.gz extractor tool (recommend downloading WinRAR) to extract the file in the cookbooks folder.
Once you have download the recipes you should have the following structure:
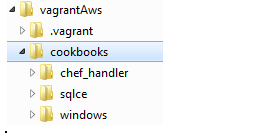
Next we’re going to execute the Vagrant file. To do this open a command prompt and navigate to the VagrantAws folder. Then type vagrant up
You should then see the following output:
C:\vagrantAws>vagrant up Bringing machine 'default' up with 'aws' provider... ==> default: Auto-generating node name for Chef... ==> default: Warning! The AWS provider doesn't support any of the Vagrant ==> default: high-level network configurations (`config.vm.network`). They ==> default: will be silently ignored. ==> default: Warning! You didn't specify a keypair to launch your instance with. ==> default: This can sometimes result in not being able to access your instance . ==> default: Warning! You're launching this instance into a VPC without an ==> default: elastic IP. Please verify you're properly connected to a VPN so ==> default: you can access this machine, otherwise Vagrant will not be able ==> default: to SSH into it. ==> default: Launching an instance with the following settings... ==> default: -- Type: t2.micro ==> default: -- AMI: ami-cdb484ae ==> default: -- Region: ap-southeast-2 ==> default: -- Subnet ID: subnet- ==> default: -- Security Groups: [" "] ==> default: -- Block Device Mapping: [] ==> default: -- Terminate On Shutdown: false ==> default: -- Monitoring: false ==> default: -- EBS optimized: false ==> default: -- Source Destination check: ==> default: -- Assigning a public IP address in a VPC: false ==> default: -- VPC tenancy specification: default ==> default: Warning! Vagrant might not be able to SSH into the instance. ==> default: Please check your security groups settings. ==> default: Waiting for instance to become "ready"... ==> default: Waiting for SSH to become available... ==> default: Machine is booted and ready for use! ==> default: Uploading with WinRM: C:/vagrantAws => /vagrant ==> default: Uploading with WinRM: C:/vagrantAws/cookbooks => C:/vagrant-chef/00 7eb444ff2fed7194a88655264e3bee/cookbooks ==> default: Running provisioner: chef_solo... ==> default: Detected Chef (latest) is already installed ==> default: Generating chef JSON and uploading... ==> default: Running chef-solo... ==> default: Starting Chef Client, version 12.4.2 ==> default: [2016-09-28T06:49:19+00:00] INFO: *** Chef 12.4.2 *** ==> default: [2016-09-28T06:49:19+00:00] INFO: Chef-client pid: 504 ==> default: [2016-09-28T06:50:01+00:00] INFO: Setting the run_list to ["recipe[ windows]", "recipe[sqlce]"] from CLI options ==> default: ==> default: [2016-09-28T06:50:01+00:00] INFO: Run List is, rec ipe[sqlce]] ==> default: [2016-09-28T06:50:01+00:00] INFO: Run List expands to [windows, sql ce] ==> default: [2016-09-28T06:50:01+00:00] INFO: Starting Chef Run for vagrant-9a2 f8af8 ==> default: [2016-09-28T06:50:01+00:00] INFO: Running start handlers ==> default: [2016-09-28T06:50:01+00:00] INFO: Start handlers complete. ==> default: Compiling Cookbooks... ==> default: ==> default: [2016-09-28T06:50:01+00:00] WARN: You are overriding windows_packag e on {:os=>"windows"} with Chef::Resource::WindowsCookbookPackage: used to be Ch ef::Resource::WindowsPackage. Use override: true if this is what you intended. ==> default: [2016-09-28T06:50:01+00:00] WARN: chef_gem[win32-api] chef_gem comp ile_time installation is deprecated ==> default: [2016-09-28T06:50:01+00:00] WARN: chef_gem[win32-api] Please set `c ompile_time false` on the resource to use the new behavior. ==> default: [2016-09-28T06:50:01+00:00] WARN: chef_gem[win32-api] or set `compi le_time true` on the resource if compile_time behavior is required. ==> default: Recipe: windows::default ==> default: * chef_gem[win32-api] action install ==> default: [2016-09-28T06:50:04+00:00] WARN: chef_gem[win32-service] chef_gem compile_time installation is deprecated ==> default: ==> default: [2016-09-28T06:50:04+00:00] WARN: chef_gem[win32-service] Please se t `compile_time false` on the resource to use the new behavior. ==> default: [2016-09-28T06:50:04+00:00] WARN: chef_gem[win32-service] or set `c ompile_time true` on the resource if compile_time behavior is required. ==> default: * chef_gem[win32-service] action install ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[windows-api] chef_gem co mpile_time installation is deprecated ==> default: ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[windows-api] Please set `compile_time false` on the resource to use the new behavior. ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[windows-api] or set `com pile_time true` on the resource if compile_time behavior is required. ==> default: * chef_gem[windows-api] action install ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[windows-pr] chef_gem com pile_time installation is deprecated ==> default: ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[windows-pr] Please set ` compile_time false` on the resource to use the new behavior. ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[windows-pr] or set `comp ile_time true` on the resource if compile_time behavior is required. ==> default: * chef_gem[windows-pr] action install ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[win32-dir] chef_gem comp ile_time installation is deprecated ==> default: ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[win32-dir] Please set `c ompile_time false` on the resource to use the new behavior. ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[win32-dir] or set `compi le_time true` on the resource if compile_time behavior is required. ==> default: * chef_gem[win32-dir] action install ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[win32-event] chef_gem co mpile_time installation is deprecated ==> default: ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[win32-event] Please set `compile_time false` on the resource to use the new behavior. ==> default: [2016-09-28T06:50:05+00:00] WARN: chef_gem[win32-event] or set `com pile_time true` on the resource if compile_time behavior is required. ==> default: * chef_gem[win32-event] action install ==> default: [2016-09-28T06:50:06+00:00] WARN: chef_gem[win32-mutex] chef_gem co mpile_time installation is deprecated ==> default: ==> default: [2016-09-28T06:50:06+00:00] WARN: chef_gem[win32-mutex] Please set `compile_time false` on the resource to use the new behavior. ==> default: [2016-09-28T06:50:06+00:00] WARN: chef_gem[win32-mutex] or set `com pile_time true` on the resource if compile_time behavior is required. ==> default: * chef_gem[win32-mutex] action install ==> default: Converging 9 resources ==> default: ==> default: * chef_gem[win32-api] action install ==> default: * chef_gem[win32-service] action install ==> default: * chef_gem[windows-api] action install ==> default: * chef_gem[windows-pr] action install ==> default: * chef_gem[win32-dir] action install ==> default: * chef_gem[win32-event] action install ==> default: * chef_gem[win32-mutex] action install ==> default: Recipe: sqlce::default ==> default: * windows_reboot[5] action nothing (skipped due to action :nothin g) ==> default: * windows_package[Microsoft SQL Server Compact 4.0 SP1 x64 ENU] a ction install ==> default: [2016-09-28T06:50:08+00:00] INFO: Installing windows_package[Micros oft SQL Server Compact 4.0 SP1 x64 ENU] version latest ==> default: ==> default: Recipe: ==> default: * remote_file[c:/var/chef/cache/SSCERuntime_x64-ENU.exe] action create ==> default: - create new file c:/var/chef/cache/SSCERuntime_x64-ENU.exe[2 016-09-28T06:50:08+00:00] INFO: remote_file[c:/var/chef/cache/SSCERuntime_x64-EN U.exe] updated file contents c:/var/chef/cache/SSCERuntime_x64-ENU.exe ==> default: ==> default: ==> default: - update content in file c:/var/chef/cache/SSCERuntime_x64-EN U.exe from none to 29e5ff ==> default: (new content is binary, diff output suppressed) ==> default: [2016-09-28T06:50:08+00:00] INFO: Starting installation...this coul d take awhile. ==> default: ==> default: ==> default: [2016-09-28T06:50:52+00:00] INFO: Chef Run complete in 51.560831 se conds ==> default: [2016-09-28T06:50:52+00:00] INFO: Skipping removal of unused files from the cache ==> default: ==> default: Running handlers: ==> default: [2016-09-28T06:50:52+00:00] INFO: Running report handlers ==> default: Running handlers complete ==> default: [2016-09-28T06:50:52+00:00] INFO: Report handlers complete ==> default: Chef Client finished, 2/16 resources updated in 98.902977 seconds C:\vagrantAws>
If you see the message Chef Client finished then congratulations! You have created an AWS using Vagrant and Chef based on an AMI that you customized.
Once you’re finished with the Vagrant instance make sure you type the command Vagrant destroy to ensure your instance is terminated and you are not charged by Amazon.




